Failure: RVT
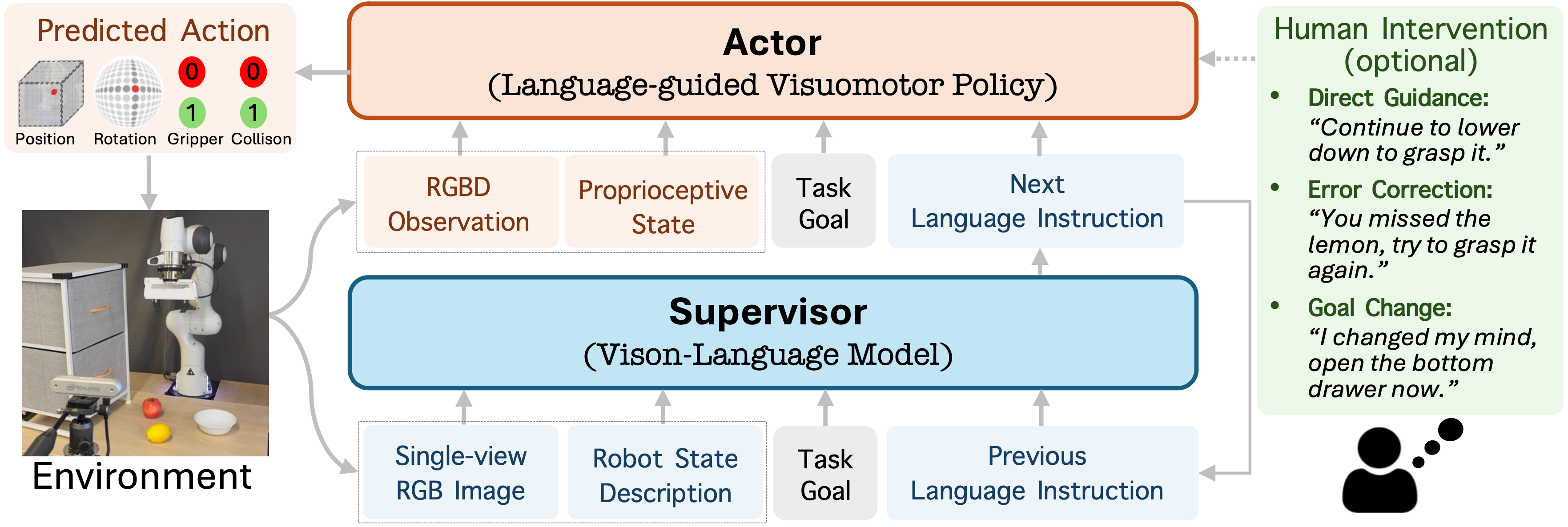
Model Architecture
RACER is a flexible supervisor-actor framework that enhances robotic manipulation through language guidance for failure recovery.
Data Augmentation Pipeline
We propose a scalable rich language-guided failure recovery data augmentation pipeline to collect new trajectories from expert demos.
Experimental Results
Real World Videos (2X default speed)
We evaluate the RVT baseline, RACER-scratch (RACER trained with rich instructions on real-world data only), RACER-simple (RACER trained with simple instructions on both simulated and real-world data), and RACER-rich (RACER trained with rich instructions on both simulated and real-world data).
(→ means there is task goal online change to test model robustness.)
Task: Open Drawer
Task Goal: Open the (top → bottom → top) drawer.
Failure: RACER-scratch
Failure: RACER-simple
Success: RACER-rich
Task: Put Item on Shelf
Task Goal: Put the Oreo on the top shelf.
Failure: RVT
Failure: RACER-scratch
Failure: RACER-simple
Success: RACER-rich
Task: Push Buttons
Task Goal: Push the blue button, then the red button.
Failure: RVT
Failure: RACER-scratch
Failure: RACER-simple
Success: RACER-rich
Task: Pick and Place Fruit
Task Goal: Put the orange into the (red → white) bowl.
Failure: RVT
Failure: RACER-scratch
Failure: RACER-simple
Success: RACER-rich
Simulation Videos
Failure Recovery with RACER
We test RACER to see if it can recover from RVT failures or self-failures in regular RLbench tasks.Task Goal: Close the navy jar.
Failure: RVT
Success: RACER
Task Goal: Stack the wine bottle to the left rack.
Failure: RVT
Success: RACER
Task Goal: Slide block to the green target.
Failure: RVT
Success: RACER
Task Goal: Stack four purple blocks.
Failure: RVT
Success: RACER
Task Goal Online Change Evaluation
We introduce a novel setting to assess the model's robustness by deliberately switching the task goal during execution.
Task Goal: Close the (olive → cyan) jar.
Failure: RVT
Success: RACER
Task Goal: Screw in the (gray → purple) light bulb.
Failure: RVT
Success: RACER
Task Goal: Open the (middle → bottom) drawer.
Failure: RVT
Success: RACER
Task Goal: Push the (maroon → green) button, then push the (green → maroon) button.
Failure: RVT
Success: RACER
Unseen Task Evaluation
We evaluate RACER on new tasks to examine its zero-shot adaptability.Task Goal: Close the bottom drawer.
Failure: RVT
Success: RACER
Task Goal: Move the block onto the green target.
Failure: RVT
Success: RACER
Task Goal: Pick up the yellow cup.
Failure: RVT
Success: RACER
Task Goal: Reach the red target.
Failure: RVT
Success: RACER
RACER with Human Language Intervention
RACER + H indicates that humans can decide to modify VLM instructions as needed. Our RACER, even though trained on rich instructions, is able to effectively understand and follow unseen human commands to enable better failure recovery when the VLM can not lead to task success.Task Goal: Put the cylinder in the shape sorter.
Failure: RACER
Success: RACER + H
Task Goal: Put the money in the bottom shelf.
Failure: RACER
Success: RACER + H
Task Goal: Sweep dirt to the short dustpan.
Failure: RACER
Success: RACER + H
Task Goal: Stack the other cups on top of the maroon cup.
Failure: RACER
Success: RACER + H
Failure Cases
Due to the limited visual understanding capabilities, the current Vision-Language Model (fine-tuned LLaVA-LLaMA3-8B in our experiments) occasionally fails to accurately recognize task failures, leading to the generation of hallucinated instructions. In addition, the visuomotor policy sometimes may also predict inappropriate actions.Task Goal: Open the top drawer.
Failure: RACER
Task Goal: Put the lemon into the red bowl.
Failure: RACER
Task Goal: Push the (blue → green) button.
Failure: RACER
Task Goal: Put the Oreo on the top shelf.
Failure: RACER
BibTeX
@misc{dai2024racerrichlanguageguidedfailure,
title={RACER: Rich Language-Guided Failure Recovery Policies for Imitation Learning},
author={Yinpei Dai and Jayjun Lee and Nima Fazeli and Joyce Chai},
year={2024},
eprint={2409.14674},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2409.14674},
}